Kernel density estimation
Kernel Density Estimation (KDE) is a non-parametric way to estimate the probability density function of a random variable. KDE is a fundamental data smoothing problem where inferences about the population are made, based on a finite data sample. It is used in various fields such as signal processing, data mining, and machine learning to analyze and visualize the underlying distribution of data.
Overview[edit]
Kernel density estimation is a method to estimate the probability density function (PDF) of a continuous random variable. It is used when the shape of the distribution is unknown, and it aims to provide a smooth estimate based on a finite sample. The KDE is a sum of kernels, usually symmetric and unimodal, which are centered at the sample points. The most common choice of kernel is the Gaussian kernel, but other kernels like Epanechnikov, Tophat, and Exponential can be used depending on the application.
Mathematical Formulation[edit]
Given a set of n independent and identically distributed samples X = {x_1, x_2, ..., x_n} from some distribution with an unknown density f, the kernel density estimator f̂ is defined as:
\[ f̂(x) = \frac{1}{nh} \sum_{i=1}^{n} K\left(\frac{x - x_i}{h}\right) \]
where K is the kernel — a non-negative function that integrates to one and has mean zero — and h is a smoothing parameter called the bandwidth. The choice of h is critical as it controls the trade-off between bias and variance in the estimate. Too small a bandwidth leads to a very bumpy density estimate (overfitting), while too large a bandwidth oversmooths the density estimate (underfitting).
Bandwidth Selection[edit]
The selection of the bandwidth h is crucial in KDE and can significantly affect the estimator's performance. Several methods for selecting the optimal bandwidth exist, including the rule of thumb, cross-validation, and plug-in approaches. The rule of thumb is simple but may not be optimal for data that is not normally distributed. Cross-validation methods, such as least squares cross-validation, aim to minimize the difference between the estimated and the true density functions. Plug-in methods provide a more automated approach to bandwidth selection but require assumptions about the underlying density.
Applications[edit]
Kernel density estimation is widely used in various fields for data analysis and visualization:
- In Economics, KDE is used to analyze income distributions and financial market data.
- In Environmental Science, it helps in modeling the distribution of species and pollution levels.
- In Machine Learning and Data Mining, KDE is employed for density estimation, clustering, and anomaly detection.
- In Signal Processing, it is used for noise reduction and signal reconstruction.
Advantages and Limitations[edit]
The main advantage of KDE is its flexibility in modeling distributions without assuming a specific parametric form. However, KDE has limitations, including sensitivity to bandwidth selection and computational complexity with large datasets. Additionally, KDE may perform poorly with multi-modal distributions or when the data has significant outliers.
See Also[edit]
References[edit]
This statistics-related article is a stub. You can help WikiMD by expanding the page. |
Kernel_density_estimation[edit]
-
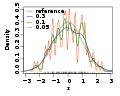 Kernel density plot
Kernel density plot -
 Comparison of 1D histogram and KDE
Comparison of 1D histogram and KDE -
 Comparison of 1D bandwidth selectors
Comparison of 1D bandwidth selectors -
 Kernel density estimation, comparison between rule of thumb and solve-the-equation bandwidth
Kernel density estimation, comparison between rule of thumb and solve-the-equation bandwidth





Medical Disclaimer: WikiMD is for informational purposes only and is not a substitute for professional medical advice. Content may be inaccurate or outdated and should not be used for diagnosis or treatment. Always consult your healthcare provider for medical decisions. Verify information with trusted sources such as CDC.gov and NIH.gov. By using this site, you agree that WikiMD is not liable for any outcomes related to its content. See full disclaimer.
Credits:Most images are courtesy of Wikimedia commons, and templates, categories Wikipedia, licensed under CC BY SA or similar.
Translate page: - East Asian
中文,
日本,
한국어,
South Asian
हिन्दी,
தமிழ்,
తెలుగు,
Urdu,
ಕನ್ನಡ,
Southeast Asian
Indonesian,
Vietnamese,
Thai,
မြန်မာဘာသာ,
বাংলা
European
español,
Deutsch,
français,
Greek,
português do Brasil,
polski,
română,
русский,
Nederlands,
norsk,
svenska,
suomi,
Italian
Middle Eastern & African
عربى,
Turkish,
Persian,
Hebrew,
Afrikaans,
isiZulu,
Kiswahili,
Other
Bulgarian,
Hungarian,
Czech,
Swedish,
മലയാളം,
मराठी,
ਪੰਜਾਬੀ,
ગુજરાતી,
Portuguese,
Ukrainian
