Multiple sequence alignment
Multiple sequence alignment (MSA) is a method used in bioinformatics to align three or more biological sequences (protein, DNA, or RNA) of similar length. By aligning these sequences, scientists can identify regions of similarity that may be a consequence of functional, structural, or evolutionary relationships between the sequences.
Overview[edit]
The goal of multiple sequence alignment is to arrange the sequences in such a way that the identities, similarities, and differences can be observed. An optimal alignment is one that displays the highest order of matching characters between the sequences, often requiring the insertion of gaps ('-') in one or more of the sequences to achieve this. These alignments are crucial for various biological analyses, including phylogenetic analysis, protein structure prediction, and the identification of conserved sequences.
Methods[edit]
Several computational algorithms and tools have been developed to perform multiple sequence alignments, each with its own advantages and limitations. The choice of tool often depends on the specific requirements of the analysis, such as the number of sequences, their length, and the desired balance between speed and accuracy.
Progressive Alignment[edit]
The most common approach to multiple sequence alignment is progressive alignment, which is implemented in tools like ClustalW and T-Coffee. This method involves creating an initial guide tree based on pairwise sequence alignments and then aligning the sequences hierarchically according to this tree.
Iterative Refinement[edit]
Iterative refinement methods, such as those used by MAFFT and MUSCLE, improve upon initial alignments by repeatedly realigning sequences or groups of sequences and adjusting the alignment to maximize an overall score.
Consensus Methods[edit]
Consensus methods, like COBALT, use information from database searches and pairwise alignments to construct a multiple sequence alignment, often resulting in more accurate alignments for sequences with known relatives in databases.
Applications[edit]
Multiple sequence alignment is a fundamental tool in molecular biology and genetics, with applications including:
- Phylogenetic Analysis: MSA is used to infer the evolutionary relationships between a set of sequences, helping to construct phylogenetic trees.
- Functional Annotation: By identifying conserved sequences across species, MSA can help predict the function of unknown proteins or genetic elements.
- Structural Prediction: Alignments can indicate structurally and functionally important regions within proteins, guiding experimental studies.
- Comparative Genomics: MSA facilitates the comparison of genomic sequences from different organisms, aiding in the identification of conserved elements and evolutionary trends.
Challenges[edit]
Despite its utility, multiple sequence alignment faces several challenges, including the computational complexity of aligning large numbers of long sequences and the difficulty of accurately placing gaps. The quality of an alignment is also dependent on the choice of parameters and the algorithm used, making it essential to understand the strengths and limitations of different MSA tools.
Conclusion[edit]
Multiple sequence alignment is a critical tool in the analysis of biological sequences, offering insights into function, structure, and evolution. As bioinformatics continues to evolve, the development of more efficient and accurate alignment algorithms remains a key area of research.
This bioinformatics-related article is a stub. You can help WikiMD by expanding the page. |
-
 Multiple sequence alignment
Multiple sequence alignment -
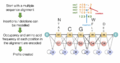 Profile HMM modelling a multiple sequence alignment
Profile HMM modelling a multiple sequence alignment -
 Non-homologous exon alignment
Non-homologous exon alignment -
 Caspase motif alignment
Caspase motif alignment



Medical Disclaimer: WikiMD is for informational purposes only and is not a substitute for professional medical advice. Content may be inaccurate or outdated and should not be used for diagnosis or treatment. Always consult your healthcare provider for medical decisions. Verify information with trusted sources such as CDC.gov and NIH.gov. By using this site, you agree that WikiMD is not liable for any outcomes related to its content. See full disclaimer.
Credits:Most images are courtesy of Wikimedia commons, and templates, categories Wikipedia, licensed under CC BY SA or similar.
Translate page: - East Asian
中文,
日本,
한국어,
South Asian
हिन्दी,
தமிழ்,
తెలుగు,
Urdu,
ಕನ್ನಡ,
Southeast Asian
Indonesian,
Vietnamese,
Thai,
မြန်မာဘာသာ,
বাংলা
European
español,
Deutsch,
français,
Greek,
português do Brasil,
polski,
română,
русский,
Nederlands,
norsk,
svenska,
suomi,
Italian
Middle Eastern & African
عربى,
Turkish,
Persian,
Hebrew,
Afrikaans,
isiZulu,
Kiswahili,
Other
Bulgarian,
Hungarian,
Czech,
Swedish,
മലയാളം,
मराठी,
ਪੰਜਾਬੀ,
ગુજરાતી,
Portuguese,
Ukrainian
